
关于事务
事务的特性
原子性(Atomic, A):要么全部执行,要么全部不执行;一致性(Consistent, C):事务的执行,使得数据库由一种正确状态转变为另一种正确的状态;隔离性(Isolation, I):在事务正确提交之前,不应该把该事务对数据的改变提供给其他事务;持久性(Durability, D):事务提交后,其结果永久保存在数据库中。
事务ACID特性的实现思想
- 原子性:是使用 undo log来实现的,如果事务执行过程中出错或者用户执行了rollback,系统通过undo log日志返回事务开始的状态。
- 持久性:使用 redo log来实现,只要redo log日志持久化了,当系统崩溃,即可通过redo log把数据恢复。
- 隔离性:通过锁以及MVCC,使事务相互隔离开。
- 一致性:通过回滚、恢复,以及并发情况下的隔离性,从而实现一致性。
并发操作带来的问题
- 脏读(Dirty Reads):一个事务在处理的过程中读取到了另一个未提交事务中的事务;
- 不可重复读(Non-Reapeatable Reads):一个事务在读取某些数据后的某个时间再次读取以前读过的数据,却发现其读出的数据已经发生了改变、或某些记录已经被删除了;
- 幻读(Phantom Reads):一个事务按相同的查询条件重新读取以前检索过的数据,却发现其他事务插入了满足其查询条件的新数据。
不可重复读 和 幻读 区别是什么?
不可重复读的重点是 修改:在同一事务中,同样的条件,第一次读的数据和第二次读的数据不一样。(因为中间有其他事务提交了修改)
幻读的重点是 新增/删除:在同一事务中,同样的条件,第一次和第二次读出来的 记录数不一样。(因为中间有其他事务提交了插入/删除)
事务的隔离级别
- 读未提交(Read UnCommitted):所有的事务都可以看到其他事务未提交的修改(很少用到业务中)。(
脏读:Y,不可重复读:Y,幻读:Y,) - 读已提交(Read Committed):只能看到其他已经提交的事务。(
脏读:N,不可重复读:Y,幻读:Y) - 可重复读(Reapeatable Read):确保同一个事务在并发读取时数据一致(MySQL 默认的事务级别)。(
脏读:N,不可重复读:N,幻读:Y) - 可串行化(Serializable):串行化读取数据(最高隔离级别,锁竞争激烈)。(
脏读:N,不可重复读:N,幻读:N)
不同的数据库支持的隔离级别不同。在 MySQL 数据库中,支持上面四种隔离级别,默认的为 Repeatable read (可重复读);而在 Oracle 数据库中,只支持 Serializable (串行化)级别和 Read committed (读已提交)这两种级别,其中默认的为 Read committed 级别。
MySQL 中有哪几种锁?
- 表级锁:开销小,加锁快;不会出现死锁;锁定粒度大,发生锁冲突的概率最高,并发度最低。
- 行级锁:开销大,加锁慢;会出现死锁;锁定粒度最小,发生锁冲突的概率最低,并发度也最高。
- 页面锁:开销和加锁时间界于表锁和行锁之间;会出现死锁;锁定粒度界于表锁和行锁之间,并发度一般。
什么是 MVCC?
多版本并发控制(MultiVersion Concurrency Control) 是一种并发控制的方法,一般用在数据库管理系统中,实现对数据库的并发访问。
为什么需要 MVCC?
主要实现对数据的隔离,解决读写之间的阻塞问题,提高读写并发度。
- 最原生的锁,锁住一个资源之后禁止其他任何线程访问。但是很多应用的场景都是 读多写少,很多数据的读取次数远远大于修改的次数,而这种读数据的操作之间进行排斥就显得很没必要;
- 所以出现了 读写锁,读锁与读锁不互斥,而写锁与写锁、写锁与读锁之间互斥,这样已经很大地提升了系统的并发能力。
- 后来人们发现并发读还是不够,又提出了一种让读写之间也不冲突的方法:快照读。就是读取数据的时候通过一种类似于 “快照” 的方式将第一眼看到的数据保存下来,这样读锁和写锁就不冲突了,不同的事务会看到自己特定版本的数据。当然,“快照”是一种概念模型,不同的数据库实现方式可能不太一样。
所以我们可以看到这样的“提高并发”的演进思路:
普通锁,串行执行 –> 读写锁,实现读读并发 –> MVCC,实现读写并发。
MVCC 解决了哪些问题?
- 读写之间的阻塞问题:可以实现并发读写;
- 降低了死锁的概率:MySQL 的 InnoDB 的 MVCC 使用了乐观锁,读数据时并不需要加锁;对于写操作,也只锁定必要的行;
- 解决一致性读的问题:一致性读也被称为快照读,当我们查询数据库在某个时间点的快照时,只能看到这个时间点之前事务提交更新的结果,而不能看到这个时间点之后事务提交的更新结果。
MVCC只在可重复读(REPEATABLE READ)和提交读(READ COMMITTED)两个隔离级别下工作。其他两个隔离级别都和MVCC不兼容,因为未提交读总是读取最新的数据行,而不是符合当前事务版本的数据行。而可串行化则会对所有读取的行都加锁。
MVCC 如何实现的?
Innodb 中使用 B+树 作为索引的数据结构,并且主键所在的索引称为 聚簇索引(ClusterIndex),聚簇索引的叶子结点保存了完整的一条数据。一张表只能有一个主键,所以也只能有一个聚簇索引,如果没有定义主键,InnoDB 将使用一个隐藏列作为聚簇索引。除了 聚簇索引,还有 二级索引(SecondaryIndex),它的叶子结点中保存的是主键。
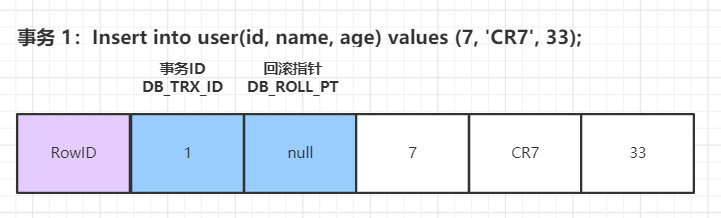
InnoDB 的叶子段中保存了数据页,数据页中保存了行记录,而在行记录中有三个个重要的隐藏记录:
- DB_ROW_ID(隐藏行 ID):隐藏的行 ID,用来生成默认的聚簇索引。如果我们创建表时没有指定聚簇索引,那么
InnoDB会使用这个隐藏 ID来创建聚簇索引。 - DB_TRX_ID(行的事务ID):操作这行数据的事务 ID,也就是最后一个对该数据进行插入或更新的事务 ID。新增一个事务时事务ID会增加,DB_TRX_ID 能够表示事务开始的先后顺序。
- DB_ROLL_PT(行的回滚指针):回滚指针,指向这行记录的
Undo Segment中的undo log。
MVCC 在 MySQL 中的实现依赖的是 undo log 和 ReadView。
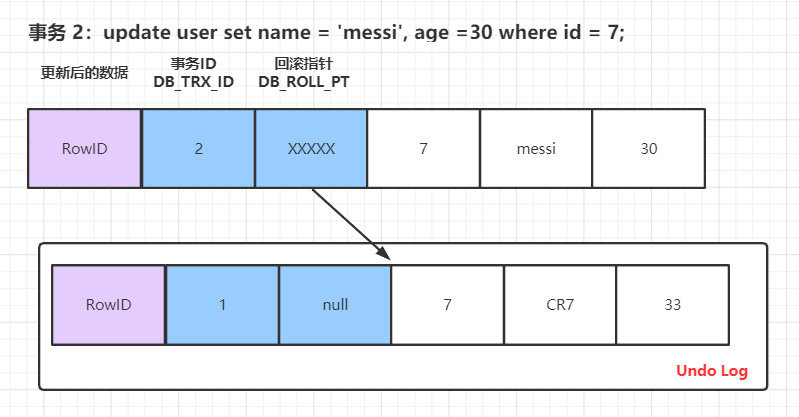
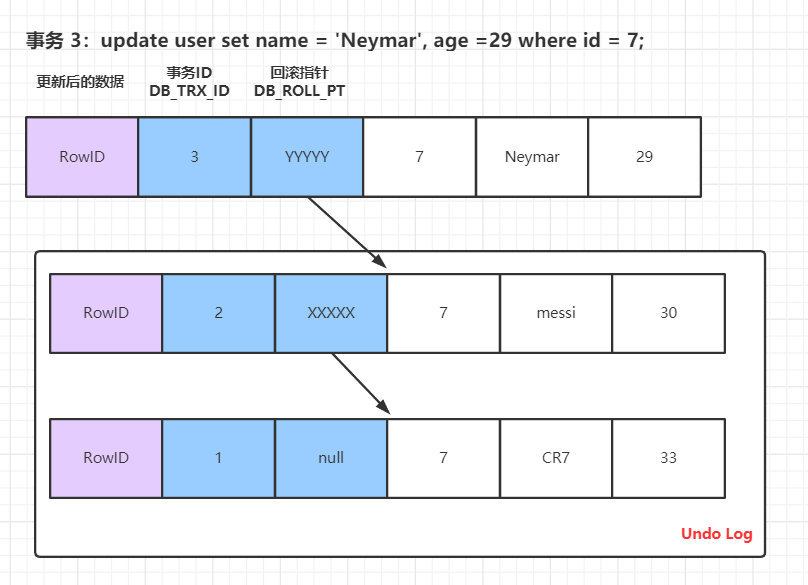
undo log:
除了记录 redo log 之外,当进行数据修改时还会记录 undo log。undo log 用于数据的撤回操作,它记录修改的反向操作,比如插入对应删除,修改对应修改为原来的数据。undo log 分为两种:Insert 和 Update,Delete 可以看做是一种特殊的 Update,即在记录上修改删除标记。而 Insert undo log 在事务提交之后可以删除,因为用不到。所以我们可以理解为:update undo log记录了数据之前的数据信息,通过这些信息可以还原到之前版本的状态。
ReadView:
也称为 一致性读视图。它并不实际存在,只是一个概念,通过 undo log 和版本计算出来,用以决定当前事务能看到哪些数据。
对于 READ UNCOMMITTED 隔离级别,所有事务直接读取数据库的最新值即可;SERIALIZABLE 隔离级别,所有请求都会加锁,同步执行。所以这对这两种情况下是不需要使用到 ReadView 的版本控制。
所以我们才说 MVCC 只支持 Read Committed 以及 Repeated Read 隔离级别的实现,而核心逻辑就是依赖 undo log 以及版本控制。针对这个问题 InnoDB 在设计上增加了ReadView 的设计,ReadView 中主要包含当前聚簇索引对应的、当前系统中还有哪些活跃的读写事务,把它们的 事务ID 放到一个列表中,我们把这个列表命名为为 m_ids。对于查询时版本数据能否被看到的判断依据是:
- 如果被访问版本的 trx_id 属性值小于 m_ids 列表中最小的事务id,表明生成该版本的事务在生成 ReadView 前已经提交,所以该版本可以被当前事务访问;
- 如果被访问版本的 trx_id 属性值大于 m_ids 列表中最大的事务id,表明生成该版本的事务在生成 ReadView 后才生成,所以该版本不可以被当前事务访问;
- 如果被访问版本的 trx_id 属性值在 m_ids 列表中最大的事务id和最小事务id之间,那就需要判断一下 trx_id 属性值是不是在 m_ids 列表中,如果在,说明创建 ReadView 时生成该版本的事务还是活跃的,该版本不可以被访问;如果不在,说明创建 ReadView 时生成该版本的事务已经被提交,该版本可以被访问。
先说结论:Read Committed 和 Repeatable Read 隔离级别的的一个非常大的区别就是它们生成 ReadView 的时机不同:
- 在
Read Committed中每次查询都会生成一个实时的ReadView,做到保证每次提交后的数据是处于当前的可见状态; - 在
Repeatable Read中,在当前事务第一次查询时生成当前的ReadView,并且当前的ReadView会一直沿用到当前事务提交,以此来保证 可重复读(Repeatale Read)。
腾讯面试:MySQL事务与MVCC如何实现的隔离级别? 中有一个例子特别好,以截图方式展示:
Read Committed 下的 ReadView:



Repeatable Read 下的 ReadView:



MySQL 中哪些存储引擎支持事务?
MySQL 服务器层不管理事务,事务是由下层的存储引擎实现的。支持事务的存储引擎有InnoDB 和 NDB Cluster。
什么是自动提交?
MySQL 默认使用 InnoDB 引擎,并且默认采用 自动提交(AUTOCOMMITTED) 模式。也就是说,如果不是显式地开启一个事务,则每一个查询都被当成一个事务执行提交操作。
MySQL 支持的存储引擎
我们主要关注三个:InnoDB、MyISAM 和 Memory。
InnoDB
MySQL 的默认事务型引擎,支持事务和外键。在你增删改查时匹配的条件字段带有索引时,InnoDB 使用 行级锁;在你增删改查时匹配的条件字段不带有索引时。InnoDB 使用的将是 表级锁。
MyISAM
旧版本MySQL 的默认存储引擎。主要特点是快,不支持事务,也不支持外键。
Memory
使用内存空间来创建表。Memory 类型的表访问非常快,因为它的数据是放在内存中的,并且默认使用 Hash 索引,但是一旦服务关闭,表中的数据就会丢失掉。
关于索引
按照数据结构分:哈希索引、B+树索引 和 全文索引。
按物理存储方式分:聚簇索引 和 二级索引。
InnoDB到底支不支持哈希索引?
InnoDB用户无法手动创建哈希索引,这一层上说,InnoDB确实不支持哈希索引;InnoDB会自调优(self-tuning),如果判定建立自适应哈希索引(Adaptive Hash Index, AHI),能够提升查询效率,InnoDB自己会建立相关哈希索引,这一层上说,InnoDB又是支持哈希索引的。
哈希索引
哈希索引(Hash Index) 基于哈希表实现,只适合精确匹配,不适合范围查找。对于每一行数据,存储引擎都会使用一个哈希函数,对改行的对应索引列计算哈希code,通过 K-V 的形式保存起来,其中“K”为哈希 code,“V”是指向改行记录的指针。
使用哈希索引,有一点需要注意:如何解决哈希冲突?就目前而言,大多数使用 “链接法”——冲突之后,在原来的位置添加一个链表结构,多个冲突值通过链表的形式保存;当查询的时候,通过哈希 code 定位到对应的链表,之后遍历链表,直到找到符合条件的。
借用《高性能 MySQL》中实例:

哈希索引的特点:
- 哈希索引只包含哈希值和行指针,不存储字段值。因此无法使用覆盖索引等相关特性;
- 哈希索引并不按照索引值顺序存储,因此不适合排序操作;
- 哈希索引不支持部分索引列匹配查找,因为计算哈希时,始终使用的是索引列的全部内容。例如,在数据列<A, B>上建立哈希索引,如果查询的只有<A>,那么无法使用该索引,因为 hash(<A, B>) 和 hash(<A>) 的结果一点关系都没有;
- 哈希索引只支持等值比较( =、IN()和 <=>(效果等同于等号,不过可以比较 NULL)),不支持任何的范围查询(比如 BETWEEN、< 等);
- 访问哈希索引的速度非常快,除非出现很多的哈希冲突,此时的查询会退化成链表的遍历;
- 如果哈希冲突很多的话,索引的维护代价将会非常高,此时对索引的增删改,回退化成对链表的增删改,**O(n)**的时间复杂度。
B+树索引
所有的数据都在叶子节点,非叶子结点只存储叶子结点的索引,且每一个叶子节点都带有指向下一个节点的指针,形成了一个有序的链表,这样就可以实现范围查询。优势:
- B+Tree 它的非叶子节点不存储数据,只存储索引,而数据会存放在叶子节点中。非叶子结点存储的索引越多,叶子结点能表示的数据就越多,同样数量情况下,树的高度越小,查找数据时进行的 IO 次数就越少。
全文索引
只支持英文,实现方式为 倒排索引:先分词,再建立对应的B+树索引。
InnoDB 中的索引策略
- 覆盖索引
- 最左前缀原则
- 索引下推
- 索引下推优化是 MySQL 5.6 引入的,可以在索引遍历过程中,对索引中包含的字段先做判断,直接过滤掉不满足条件的记录,减少回表次数。
InnoDB 中创建索引有什么原则
- 最左前缀匹配原则
- 频繁作为查询条件的字段才去创建索引
- 频繁更新的字段不适合创建索引
- 索引列不能参与计算,不能有函数操作
- 优先考虑扩展索引,而不是新建索引,避免不必要的索引
- 在order by或者group by子句中,创建索引需要注意顺序
- 区分度低的数据列不适合做索引列(如性别)
- 定义有外键的数据列一定要建立索引。
- 对于定义为text、image数据类型的列不要建立索引。
- 删除不再使用或者很少使用的索引
MySQL 分库分表
分库分表方案
- 水平分库:以字段为依据,按照一定策略(hash、range等),将一个库中的数据拆分到多个库中。
- 水平分表:以字段为依据,按照一定策略(hash、range等),将一个表中的数据拆分到多个表中。
- 垂直分库:以表为依据,按照业务归属不同,将不同的表拆分到不同的库中。
- 垂直分表:以字段为依据,按照字段的活跃性,将表中字段拆到不同的表(主表和扩展表)中。
分库分表可能遇到的问题
- 事务问题:需要用分布式事务啦
- 跨节点Join的问题:解决这一问题可以分两次查询实现
- 跨节点的count,order by,group by以及聚合函数问题:分别在各个节点上得到结果后在应用程序端进行合并。
- 数据迁移,容量规划,扩容等问题
- ID问题:数据库被切分后,不能再依赖数据库自身的主键生成机制啦,最简单可以考虑UUID
- 跨分片的排序分页问题(后台加大pagesize处理?)
MySQL InnoDB 索引为什么使用 B+树?
可以从几个维度去看这个问题,查询是否够快,效率是否稳定,存储数据多少,以及查找磁盘次数,为什么不是二叉树,为什么不是平衡二叉树,为什么不是B树,而偏偏是B+树呢?
为什么不是一般二叉树?
如果二叉树特殊化为一个链表,相当于全表扫描。平衡二叉树相比于二叉查找树来说,查找效率更稳定,总体的查找速度也更快。
为什么不是平衡二叉树呢?
我们知道,在内存比在磁盘的数据,查询效率快得多。如果树这种数据结构作为索引,那我们每查找一次数据就需要从磁盘中读取一个节点,也就是我们说的一个磁盘块,但是平衡二叉树可是每个节点只存储一个键值和数据的,如果是B树,可以存储更多的节点数据,树的高度也会降低,因此读取磁盘的次数就降下来啦,查询效率就快啦。
那为什么不是B树而是B+树呢?
- B+树非叶子节点上是不存储数据的,仅存储键值,而B树节点中不仅存储键值,也会存储数据。innodb中页的默认大小是16KB,如果不存储数据,那么就会存储更多的键值,相应的树的阶数(节点的子节点树)就会更大,树就会更矮更胖,如此一来我们查找数据进行磁盘的IO次数有会再次减少,数据查询的效率也会更快。
- B+树索引的所有数据均存储在叶子节点,而且数据是按照顺序排列的,链表连着的。那么B+树使得范围查找,排序查找,分组查找以及去重查找变得异常简单。