Docker

一、前言
Docker 是一个开源的应用容器引擎,可以让开发者将他们的应用以及依赖打包到一个可移植的容器中,这个容器可以发布并运行在任何流行的 Linux 环境下。
理解:Docker 是什么?Docker 是一个容器,这个容器是可以随便移动的,就像一个箱子;箱子里是什么东西呢?箱子里是开发者写好的应用以及这个应用运行时的环境,即箱子里面是一个可以独立运行的沙盒应用;这个箱子有什么特点呢?可以随便搬动,并且能在任何 Linux 系统上直接运行(现在主流的服务器应用大多数都部署在 Linux 系统中)。
Docker 的构想是实现Build, Ship, Run Anywhere,即通过对应用的 封装(Packaging) 、 分发(Distribution) 、 部署(Deployment) 、 运行(Runtime) 的生命周期进行管理,达到应用组件级别的“一次封装,到处运行”。这里的应用组件,既可以是一个 web 应用、一个编译环境,也可以是拥有运行环境的 web 服务,也可以是一套数据库平台服务,甚至是一个操作系统或者集群。
二、Docker 架构
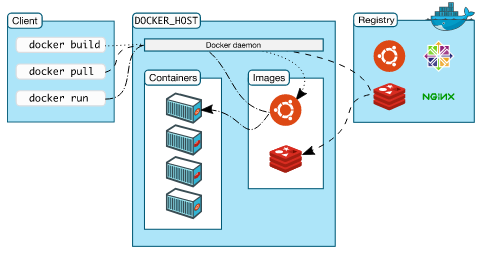
Docker 使用客户端-服务端架构。服务端负责构建、运行应用和分发容器(这个过程我是这样理解的:从上图可以看到有几个不同的角色:Client、daemon、registry、image 和 container,其中 registry 代表的是仓库,用来存储 image,同时我们也可以把 registry 中的 image(镜像)pull 到本地,进行修改之后 commit 回去,形成新的 image 存放在 registry,同时我们可以基于某个 image,在其中创建新的容器,这个容器中就是我们的应用和环境),客户端负责提供用户界面;Docker 客户端和守护进程之间使用 RESTful API,通过 unix 套接字或者网络接口进行通信,当我们使用 docker run 这样的命令时,客户端会将这些命令发送给他们的守护进程,然后守护进程执行这些命令;守护进程监听 Docker 客户端的请求并且管理服务端已有的 Docker 对象,如镜像、容器、网络。
1. Registry(注册表)
Docker Registry 用来存储 Docker 镜像。Docker Hub 是任何人都可以使用的公共注册中心,Docker 配置为默认在 Docker Hub 上查找镜像。当然你也可以运行自己的私人 Registry。
当我们使用 docker pull 或者 docker run 的时候,将会从配置的 Registry 中提取所需要的镜像;使用 docker push 时,当前的镜像也将被推送到配置的 Registry 中。
2. Image(镜像)
镜像是只读的,是用于创建一个容器的指令模板。通常情况下,一个镜像是基于另一个镜像,再加上自己的一些自定义配置形成的。举个例子,我们可以基于 Ubuntu 系统,在其基础上安装 nginx 以及其他 webserver 服务,以及这个服务运行时的各种配置信息,这样就行成了一个新的镜像。
常见的虚拟机镜像,通常是由提供者打包成镜像文件,安装者从网上下载或是其他方式获得,恢复到虚拟机中的文件系统里;而 Docker 的镜像必须通过 Docker 打包,也必须通过 Docker 下载或导入后使用,不能单独直接恢复成容器中的文件系统。这样虽然失去了灵活性,但固定的格式意味着可以很轻松的在不同的服务器间传递 Docker 镜像,配合 Docker 自身对镜像的管理功能,使得在不同的机器中传递和共享 Docker 变得非常方便,这也是 Docker 能够提升工作效率的一处体现。
通俗地讲,可以将 Docker 镜像理解为包含应用程序以及运行环境的基础文件系统,在容器启动的过程中,它以只读的方式被用于创建容器的运行环境。
Docker 镜像其实是由基于 UnionFS 文件系统的一组镜像层依次挂载而得,而每个镜像层包含的其实是对上一镜像层的修改,这些修改其实是发生在容器运行的过程中的。所以,也可以反过来理解,镜像是对容器运行环境进行持久化存储的结果。
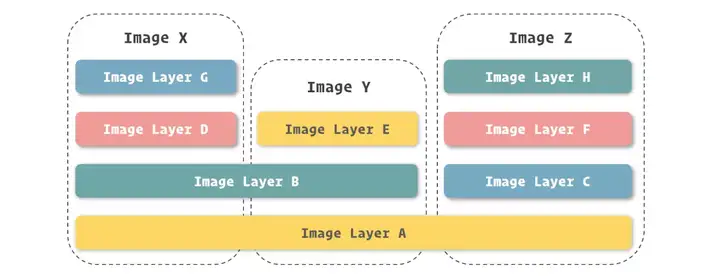
对于每一个记录文件系统修改的镜像层来说,Docker 都会根据它们的信息生成了一个 Hash 码,足以保证全球唯一性,这种编码(64 长度的字符串)的形式在 Docker 很多地方都有体现。由于镜像每层都有唯一的编码,就能够区分不同的镜像层并能保证它们的内容与编码是一致的,这带来了另一项好处,允许在镜像之间共享镜像层。举一个例子,由 Docker 官方提供的两个镜像 ElasticSearch 镜像和 Jenkins 镜像都是在 OpenJDK 镜像之上修改而得,实际使用的时候,这两个镜像是可以共用 OpenJDK 镜像内部的镜像层的。这带来的一项好处就是让镜像可以共用存储空间,达到 1+1<2 的效果,为在同一台机器里存放众多镜像提供了可能。
2.1 镜像的命名
镜像的命名由三部分组成:username、repository 和 tag,他们的组织规则入下:
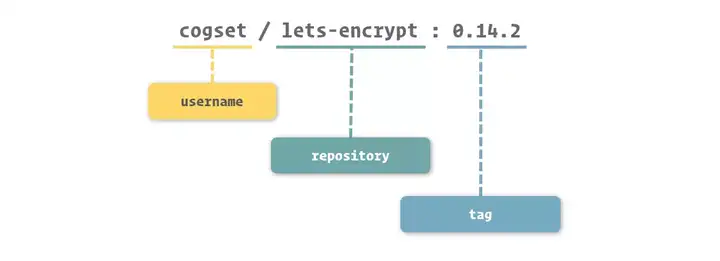
username 指上传镜像的用户;repository 表示镜像内容,形成对镜像的表意描述。有的镜像没有 username,这表明此镜像是由 Docker 官方进行维护的。
repository 表示镜像内容,形成对镜像的表意描述,通常采用的是软件名,这样的原因是,通常情况下,我们只在一个容器中运行一个应用,这样的命名可以更加方便的帮助我们识别镜像中的内容。
tag 表示镜像版本,是对同一种镜像进行更细层次区分的方法,也是最终识别镜像的关键部分。Docker 每次构建镜像的内容也就有所不同,具体体现就是镜像层以及它们的 ID 都会产生变化,使用 tag 可以很好的区分和标识这些变化。tag 一般以版本号来命名。
2.3 Container(容器)
**容器是镜像的可运行实例。**默认情况下,一个容器和另外的容器机器主机相隔离,但是这都是可配置的。
三、 概念理解
先说结论:一个”容器“,实际上是由 Linux Namespace 、 Linux Cgroups 和 rootfs 三种技术构建出来的进程的隔离环境。
1. LXC(Linux Container)
Docker 其实是容器化技术的具体实现之一,采用 Golang 语言开发。很多人认为 Docker 是一种更轻量级的虚拟机,但事实上不是这样的,Docker 和虚拟机有本质的区别。容器在本质上讲,就是运行在操作系统上的一个进程,只不过加入了对资源的隔离和限制。Docker 正是基于容器的这个设计思想,采用 Linux Container 技术实现的核心管理引擎。
为什么要进行这种设计呢?在默认情况下,一个操作系统里所有运行的进程共享 CPU 和内存资源,如果设计不当,在最极端的情况下,如果某进程出现死循环可能会耗尽所有的系统资源,其他的进程也会受到影响,这在企业级产品的场景下是不可接受的。
不过,对资源进行隔离并不是新的发明,Linux 系统本身就支持操作系统级层面的虚拟化技术,叫做 Linux Container,即 LXC 的全称,它的作用是在操作系统的层次上为进程提供虚拟的执行环境,一个虚拟的执行环境就是一个容器。可以为容器绑定特定的 cpu 和 memory 节点,分配特定比例的 cpu 时间、IO 时间,限制可以使用的内存大小(包括内存和是 swap 空间),提供 device 访问控制,提供独立的 namespace(网络、pid、ipc、mnt、uts)。
LXC,一种“操作系统层虚拟化”技术,为“linux 内核”容器功能的一个“用户空间接口”。LXC(LinuxContainer)是来自于 Sourceforge 网站上的开源项目,LXC 给 Linux 用户提供了用户空间的工具集,用户可以通过 LXC 创建和管理容器,在容器中创建运行操作系统就可以有效的隔离多个操作系统,实现操作系统级的虚拟化。最初的 Docker 容器技术基于 LXC 进行构建,后来 Docker 在自己的内核中刨除了 LXC。它将应用软件系统打包成一个软件容器(Container),内含应用软件本身的代码,以及所需要的操作系统核心和库。透过统一的名字空间和共享 API 来分配不同软件容器的可用硬件资源,创造出应用程序的独立沙箱运行环境,使得 Linux 用户可以容易的创建和管理系统或应用容器。
从前面的介绍中我们可以了解到,LXC 能够创建容器用于 Linux 系统的虚拟化,而 LXC 作为用户层管理工具主要提供了管理容器的接口,对实现容器的机制进行了封装隐藏,下面将对 LXC 容器的实现机制进行分析。LXC 有三大特色: cgroup 、 namespace 和 unionFS 。
- namespace
这是另一个维度的资源隔离技术,与我们平常 C++程序开发中的 namespace 可以相类比。
如果 cgroup 设计出来是为了隔离上面所描述的物理资源,那么 namespace 则用来隔离 PID、IPC、NETWORK 等系统资源。每一个 namespace 中的资源对其他 namespace 都是透明的,互不干扰。在每一个 namespace 内部,每一个用户都拥有属于自己的 init 进程,pid = 1,对于该用户来说,仿佛他独占了一台物理的 Linux 虚拟机。但是事实上,这个 namespace 中的 pid,只是其父容器的一个子进程而已。
通过下图来加深理解:
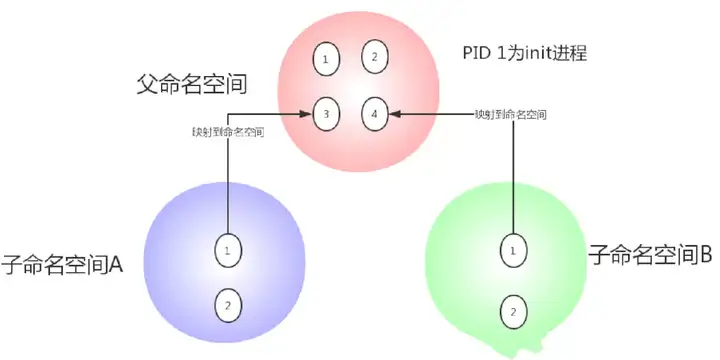
父容器有两个子容器,父容器的命名空间里有两个进程,id 分别为 3 和 4, 映射到两个子命名空间后,分别成为其 init 进程,这样命名空间 A 和 B 的用户都认为自己独占整台服务器。对于每一个命名空间,从用户看起来,应该像一台单独的 Linux 计算机一样,有自己的 init 进程(PID 为 1),其他进程的 PID 依次递增,A 和 B 空间都有 PID 为 1 的 init 进程,子容器的进程映射到父容器的进程上,父容器可以知道每一个子容器的运行状态,而子容器与子容器之间是隔离的。从图中我们可以看到,进程 3 在父命名空间里面 PID 为 3,但是在子命名空间内,他就是 1. 也就是说用户从子命名空间 A 内看进程 3 就像 init 进程一样,以为这个进程是自己的初始化进程,但是从整个 host 来看,他其实只是 3 号进程虚拟化出来的一个空间而已。
【参考】 DOCKER 基础技术:LINUX NAMESPACE(上)
DOCKER 基础技术:LINUX NAMESPACE(下)
- cgroup(control group)
前面,我们介绍了 Linux Namespace,但是Namespace 解决的问题主要是环境隔离的问题,这只是虚拟化中最最基础的一步,我们还需要解决对计算机资源使用上的隔离。也就是说,虽然你通过 Namespace 把我 Jail 到一个特定的环境中去了,但是我在其中的进程使用用 CPU、内存、磁盘等这些计算资源其实还是可以随心所欲的。所以,我们希望对进程进行资源利用上的限制或控制。这就是 Linux CGroup 出来了的原因。
cgroup 用来限定一个进程的资源使用,由 Linux 内核支持,可以限制和隔离 Linux 进程组(process groups)所使用的资源,比如 CPU、内存、磁盘和网络 IO,是 LXC 技术的物理基础。
主要提供了如下功能:
Resource limitation: 限制资源使用,比如内存使用上限以及文件系统的缓存限制。
Prioritization: 优先级控制,比如:CPU 利用和磁盘 IO 吞吐。
Accounting: 一些审计或一些统计,主要目的是为了计费。
Control: 挂起进程,恢复执行进程。
使 用 cgroup,系 统 管 理 员 可 更 具 体 地 控 制 对 系 统 资 源 的 分 配 、优先顺序、拒绝、监控和管理。可以更好地根据任务和用户分配硬件资源,提高总体效率。
在实践中,系统管理员一般会利用 CGroup 做下面这些事(有点像为某个虚拟机分配资源似的):
隔离一个进程集合(比如:nginx 的所有进程),并限制他们所消费的资源,比如绑定 CPU 的核。
为这组进程 分配其足够使用的内存
为这组进程分配相应的网络带宽和磁盘存储限制
限制访问某些设备(通过设置设备的白名单)
- unionFS
unionFS 的含义是,可以把文件系统上多个目录内容联合挂载到同一个目录下,而目录的物理位置是分开的。
我们来看一个例子(例子来自耗子叔的文章,但是原文中的不完善,我在这里补充一下):
首先我们建立两个目录(fruits 和 vegetables),并在这两个目录中新建一些文件:
# 创建目录
>>> mkdir fruits
>>> mkdir vegetables
>>> echo "apple in fruits" > ./fruits/apple
>>> echo "tomato in fruits" > ./fruits/tomato
>>> echo "carrots in vegetables" > ./vegetables/carrots
>>> echo "tomato in vegetables" > ./vegetables/tomato
# 查看当前目录结构
>>> tree .
.
├── fruits
│ ├── apple
│ └── tomato
└── vegetables
├── carrots
└── tomato
然后使用 aufs 进行 mount,注意 fruits 和 vegetables 的顺序:
# 创建mount目录
>>> mkdir mnt
# 把水果目录和蔬菜目录union mount到 ./mnt目录中
>>> sudo mount -t aufs -o dirs=./fruits:./vegetables none ./mnt
# 看一下当前的结构
>>> tree ./mnt
./mnt
├── apple
├── carrots
└── tomato
# 看一下mnt中的内容
>>> cat ./mnt/apple
apple in fruits
>>> cat ./mnt/carrots
carrots in vegetables
>>> cat ./mnt/tomato
tomato in fruits
我们发现,fruits 和 vegetables 中的文件被 merge 到了一起,并且同名的文件只出现一次,默认以第一个文件夹为准。
下面我们看一下 merge 后的文件和源文件之间的映射关系。第一步,修改源文件,merge 后的文件是否会受影响?
# 修改fruits的apple
>>> echo "append 1 after fruits.apple" >> ./fruits/apple
>>> cat ./fruits/apple
apple in fruits
append 1 after fruits.apple
# 查看mnt中的apple
>>> cat ./mnt/apple
apple in fruits
append 1 after fruits.apple
# 修改vevegtbles中的carrots
echo "append 2 after vegetables.carrots" >> ./vevegtbles/carrots
>>> cat ./vevegtbles/carrots
carrots in vegetables
append 2 after vegetables.carrots
# 查看mnt中的carrots
>>> cat ./mnt/carrots
carrots in vegetables
append 2 after vegetables.carrots
由此可以得到:修改源文件,merge 后的文件也会同步改变。
我们继续往下走:修改 mnt 中的文件,源文件会受到什么影响?
>>> echo "append 3 after mnt.apple" >> ./mnt/apple
# 查看源文件
>>> cat ./fruits/apple
apple in fruits
append 1 after fruits.apple
append 3 after mnt.apple
# 重点来了,修改mnt.carrots
>>> echo "append 4 in mnt.carrots" >> ./mnt/carrots
tree .
.
├── fruits
│ ├── apple
│ ├── carrots
| └── tomato
└── vegetables
├── carrots
└── tomato
>>> cat ./fruits/carrots
append 2 after vegetables.carrots
# 查看mnt中的carrots
>>> cat ./mnt/carrots
carrots in vegetables
append 2 after vegetables.carrots
append 4 in mnt.carrots
我们 merge 后的第一个目录没有的文件,竟然将该文件复制进了第一个文件,然后进行了修改!
docker 通过一个叫做 copy-on-write (CoW) 的策略来保证 base 镜像的安全性,以及更高的性能和空间利用率。
Copy-on-write is a strategy of sharing and copying files for maximum efficiency. If a file or directory exists in a lower layer within the image, and another layer (including the writable layer) needs read access to it, it just uses the existing file. The first time another layer needs to modify the file (when building the image or running the container), the file is copied into that layer and modified. This minimizes I/O and the size of each of the subsequent layers. These advantages are explained in more depth below.
- 当容器需要读取文件的时候: 从最上层镜像开始查找,往下找,找到文件后读取并放入内存,若已经在内存中了,直接使用。(即,同一台机器上运行的 docker 容器共享运行时相同的文件)。
- 当容器需要添加文件的时候: 直接在最上面的容器层可写层添加文件,不会影响镜像层。
- 当容器需要修改文件的时候: 从上往下层寻找文件,找到后,复制到容器可写层,然后,对容器来说,可以看到的是容器层的这个文件,看不到镜像层里的文件。容器在容器层修改这个文件。
- 当容器需要删除文件的时候: 从上往下层寻找文件,找到后在容器中记录删除。即,并不会真正的删除文件,而是软删除。这将导致镜像体积只会增加,不会减少。
那么,这种 UnionFS 有什么用?
历史上,有一个叫 Knoppix 的 Linux 发行版,其主要用于 Linux 演示、光盘教学、系统急救,以及商业产品的演示,不需要硬盘安装,直接把 CD/DVD 上的 image 运行在一个可写的存储设备上(比如一个 U 盘上),其实,也就是把 CD/DVD 这个文件系统和 USB 这个可写的系统给联合 mount 起来,这样你对 CD/DVD 上的 image 做的任何改动都会在被应用在 U 盘上,于是乎,你可以对 CD/DVD 上的内容进行任意的修改,因为改动都在 U 盘上,所以你改不坏原来的东西。
我们可以再发挥一下想像力,你也可以把一个目录,比如你的源代码,作为一个只读的 template,和另一个你的 working directory 给 union 在一起,然后你就可以做各种修改而不用害怕会把源代码改坏了。有点像一个 ad hoc snapshot。
Docker 把 UnionFS 的想像力发挥到了容器的镜像。你是否还记得我在介绍 Linux Namespace 上篇中用 mount namespace 和 chroot 山寨了一镜像。现在当你看过了这个 UnionFS 的技术后,你是不是就明白了,你完全可以用 UnionFS 这样的技术做出分层的镜像来。
这就是 Docker 容器镜像分层实现的技术基础。所以我们说,Docker 中新的镜像并不是从头开始制作的,而是从一些 base 镜像的基础上创建并加上自定义修改而形成的,这些自定义的设置不会影响原来的 base 镜像。和 git 中的 commit 很像。这种设计的优点就是资源共享。试想一下,一台宿主机上运行 100 个基于 debian base 镜像的容器,难道每个容器中都保存一份重复的 debian 的拷贝吗?这显然不合理。借助 Linux 的 unionFS,宿主机只需要在磁盘上保存一份 base 镜像,内存中也加载一份,就能被所有基于这个 base 镜像的容器所共享。(举一个后面会遇到的例子:当我们使用 docker pull ubuntu:latest 这个命令的时候,可以看到如下的输出信息,从这个过程我们可以看出,镜像文件一般由若干层组成,使用 docker pull 下载中会获取并输出镜像的各层信息,当不同的镜像包括相同的层时,本地仅存了层的其中一份,减小了存储空间。)
>>> docker pull ubuntu:latest
latest: Pulling from library/ubuntu
35c102085707: Pull complete
251f5509d51d: Pull complete
8e829fe70a46: Pull complete
6001e1789921: Pull complete
Digest: sha256:66cd4dd8aaefc3f19afd407391cda0bc5a0ade546e9819a392d8a4bd5056314e
Status: Downloaded newer image for ubuntu:latest
>>> docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
centos latest 67fa590cfc1c 5 hours ago 202MB
ubuntu latest a2a15febcdf3 5 days ago 64.2MB
可以看到最新的 ubuntu 镜像只有 64M,而 centos 也只有 202M,是不是觉得太小了?这是因为 docker 在运行的时候直接使用了 docker 宿主机器的 kernel。
Linux 操作系统由内核空间和用户空间组成。

内核空间是 kernel,用户空间是 rootfs, 不同 Linux 发行版的区别主要是 rootfs. 比如 Ubuntu 14.04 使用 upstart 管理服务,apt 管理软件包;而 CentOS 7 使用 systemd 和 yum。这些都是用户空间上的区别,Linux kernel 差别不大。
所以 Docker 可以同时支持多种 Linux 镜像,模拟出多种操作系统环境。

需要注意的是,base 镜像只是用户空间和发行版一致。kernel 使用的是 docker 宿主机器的 kernel。例如 CentOS 7 使用 3.x.x 的 kernel,如果 Docker Host 是 Ubuntu 16.04(比如我们的实验环境),那么在 CentOS 容器中使用的实际是是 Host 4.x.x 的 kernel。
AUFS 有所有 Union FS 的特性,把多个目录,合并成同一个目录,并可以为每个需要合并的目录指定相应的权限,实时的添加、删除、修改已经被 mount 好的目录。AUFS 的 whiteout 的实现是通过在上层的可写的目录下建立对应的 whiteout 隐藏文件来实现的。也就是说,如果我们想要删除某个地分支的文件,只需要在高分支的可写目录下,建立一个 whiteout的名字是’.wh.<filename>’ ,那么对应的下层的 <filename> 就会被删除,即使不被删除,也会不可见。
当用 docker run 启动某个容器的时候,实际上容器的顶部添加了一个新的可写层,这个可写层也叫容器层。容器启动后,它里面的所有对容器的修改包括文件的增删改都只会发生在最顶部的容器层,而对下面的只读镜像层没有影响。
【参考】DOCKER 基础技术:AUFS
四、 Docker 镜像
刚开始学习时,很多人会分不清 镜像(image) 和 容器(container) 的区别。这里引用 Stackverflow:What is the difference between a Docker image and a container?的解释:
An instance of an image is called a container. You have an image, which is a set of layers as you describe. If you start this image, you have a running container of this image. You can have many running containers of the same image.
the image is the recipe, the container is the cake ; -) you can make as many cakes as you like with a given recipe.
镜像可以理解为一种 构建时(build-in)结构 ,而容器可以理解为一种 运行时(run-time)结构 。我们通常使用 docker service create 和 docker container run 从某个镜像启动一个或者多个容器。一旦容器从镜像启动之后,二者就变成了互相依赖的关系,并且在镜像启动的容器全部停止之前,镜像是无法被删除的。
1. 镜像命名
docker pull DNS名称/用户名/镜像名:tag名
上述命令可以简写成 docker pull 镜像名 ,表示从 Docker 官方仓库中,默认拉取 tag 为 latest 的镜像。
2. 常用命令
docker image pull xxx: 下载镜像
docker image ls: 列出当前主机上的所有镜像(-a 列出所有 -p只列出id)
docker image inspect xxx: 查看当前image的详情
docker image rm xxx: 删除某个镜像(docker image rm $(docker image ls -a) -f 删除本机上所有的镜像)
docker container rm $(docker container ls -a | awk '$1 !="CONTAINER" {print $1}') -f:删除所有的container
四、 Dockerfile
在实际开发中,几乎都是采用 Dockerfile 来制作镜像,而很少会采用将容器整个提交的方式。Dockerfile 是 Docker 中用于定义镜像自动化构建流程的配置文件。在 Dockerfile 中,包含了构建一个镜像过程中需要执行的命令以及其他操作。常见的 Docker 命令如下:
FROM
之前提到过,我们不会从 0 开始构建一个镜像,而是会选择一个已经存在的镜像作为 base。FROM 用于指定一个 base 镜像,之后的所有操作都是基于这个 base 镜像来执行的,Docker 会先获取这个给出的 base 镜像,然后在这个 base 镜像上进行后面的构建操作。FROM 支持三种格式:
FROM <image> [AS <name>]
FROM <image>[:<tag>] [AS <name>]
FROM <image>[@<digest>] [AS <name>]
一般使用第二种,当 tag 不写时,默认为 latest。除了选择现有的镜像之外,Docker 还存在一个特殊的镜像,叫 scratch,它表示一个空白的镜像。如果你以 scratch 为基础镜像的话,意味着你不以任何镜像为基础,接下来所写的指令将作为镜像第一层开始存在。不以任何系统为基础,直接将可执行文件复制进镜像的做法并不罕见,比如 swarm、coreos/etcd。对于 Linux 下静态编译的程序来说,并不需要有操作系统提供运行时支持,所需的一切库都已经在可执行文件里了,因此直接 FROM scratch 会让镜像体积更加小巧。使用 Go 语言 开发的应用很多会使用这种方式来制作镜像,这也是为什么有人认为 Go 是特别适合容器微服务架构的语言的原因之一。
RUN
RUN 用来在构建 docker 镜像的过程中执行命令行命令。但是并不建议一条 shell 命令一个 RUN。为什么呢?之前说过,Dockerfile 中的每一条指令都会建立一层,RUN 也不例外。每一个 RUN 行为,就和刚才我们手工建立镜像的过程一样:新建立一层,在其上执行这条命令,执行结束后,commit 这一层的修改,构成新的镜像。如果有很多 RUN,会出现很多运行时不需要的东西,结果就是产生了非常臃肿、非常多层的镜像, 不仅增加了构建部署的时间,也很容易出错。正确的做法是将这些命令通过&&符号串起来,如果需要换行就是用“\”来连接两行,简化为一层,并且及时删除下载的 tgz 文件等。因此,在撰写 Dockerfile 的时候,要经常提醒自己,这并不是在写 Shell 脚本,而是在定义每一层该如何构建。
ENV
用于设置环境变量。例如:
ENV VERSION=1.0 DEBUG=on \
NAME="Happy Feet"
这个例子中演示了如何换行,以及对含有空格的值用双引号括起来的办法,这和 Shell 下的行为是一致的。定义了环境变量,那么在后续的指令中,就可以使用这个环境变量。
WORKDIR
Dockerfile 中的 WORKDIR 指令用于指定容器的一个目录, 容器启动时执行的命令会在该目录下执行。相当于设置根目录。当使用相对目录的情况下,采用上一个 WORKDIR 指定的目录作为基准,相当与 cd 命令,但不同的是指定了 WORKDIR 后,容器启动时执行的命令会在该目录下执行。
CMD 与 ENTRYPOINT
之前了解到,Docker 不是虚拟机,容器就是进程。既然是进程,那么启动容器的时候,需要指定所运行的程序以及参数。CMD 就是用于默认的容器主进程的启动命令的。当然 Dockerfile 中也可以没有 CMD,在运行时指定也可以。
另外需要注意的是,容器中运行一个服务没有前后台的概念。为什么呢?对于容器而言,其启动程序就是容器应用进程,容器就是为了主进程而存在的,主进程退出,容器就失去了存在的意义,从而退出,其它辅助进程不是它需要关心的东西。举个例子,我们使用了
CMD service nginx start
然后发现容器执行后就立即退出了,甚至在容器内去使用 systemctl 命令发现根本执行不了。原因是使用“service nginx start”,则是希望 upstart 以后以后台守护进程的形式启动 nginx 服务,但是“CMD service nginx start”会被理解成 CMD [ “sh”, “-c”, “service nginx start”],因此主进程实际上是 sh,那么当 service nginx start 命令结束以后,sh 也就消失了,sh 作为主进程退出了,自然就会使容器退出。正确做法是直接执行 nginx 可执行文件,并且要以前台的形式运行,如
CMD nginx -g 'daemon off;'
ENTRYPOINT 的目的和 CMD 一样,都是指定容器启动程序以及参数。当指定了 ENTRYPOINT 后,CMD 的含义就发生了改变,不再是直接的运行其命令,而是将 CMD 的内容作为参数传给 ENTRYPOINT 指令,换句话说实际执行时,将变为
<ENTRYPOINT> "<CMD>"
COPY 与 ADD
COPY 指令将从构建上下文目录中 <源路径> 的文件/目录复制到新的一层的镜像内的 <目标路径> 位置。<源路径> 可以是多个,甚至可以是通配符,其通配符规则要满足 Go 的 filepath. Match 规则,比如:
COPY package.json /usr/src/app/
<目标路径> 可以是容器内的绝对路径,也可以是相对于工作目录的相对路径(工作目录可以用 WORKDIR 指令来指定)。目标路径不需要事先创建,如果目录不存在会在复制文件前先行创建缺失目录。此外,还需要注意一点,使用 COPY 指令,源文件的各种元数据都会保留。比如读、写、执行权限、文件变更时间等。
在使用该指令的时候还可以加上 –chown=
COPY --chown=55:mygroup files* /mydir/
COPY --chown=bin files* /mydir/
COPY --chown=1 files* /mydir/
COPY --chown=10:11 files* /mydir/
ADD 指令和 COPY 的格式和性质基本一致。但是在 COPY 基础上增加了一些功能。使用 ADD 时,如果原路径是一个 url 或者压缩包,Docker 引擎会将这个 url 下载或者将压缩包解压之后再复制。看情况使用即可。
EXPOSE
声明运行时容器提供服务的端口,这只是一个声明(即打算、推荐用这个端口),在运行是并不会因为这个声明而开启这个端口的服务。在 Dockerfile 中写入这样的声明有两个好处:
帮助镜像使用者理解这个镜像服务推荐使用的端口,以方便配置映射;
在运行时使用端口映射,也就是
docker run -P时(-P表示随机映射),会自动映射EXPOSE的端口。需要区分
docker run -P和docker run -p <宿主端口>:<容器端口> -p <宿主端口>:<容器端口>:
docker run -P会随机映射宿主端口到Dockerfile中的EXPOSE,如:
>>> cat Dockerfile
FROM nginx:latest
EXPOST 80 90
>>> docker build -t nginx-test .
>>> docker run -d -P nginx-test
>>> docker container ls
# 输出
9e3f0b2d6569 nginx-test "/docker-entrypoint.…" 8 seconds ago Up 7 seconds 0.0.0.0:32769->80/tcp, 0.0.0.0:32768->90/tcp compassionate_pascal
这其中会将本机的 32769 和 32768 暴露出来,同时映射到容器中的 80 和 90 。
docker run -p <宿主端口>:<容器端口>指定宿主机和容器的端口:
>>> docker run -d -p 8080:80 nginx-test
此时访问宿主机的 curl 宿主机IP:8080 会映射到容器内的 80 端口。
VOLUMN
docker 提供一种机制,可以将宿主机上的某个目录与容器的某个目录(称为挂载点,或者卷)关联起来,容器挂载点下的内容就是宿主机对应目录下的内容,可以有以下效果:
- 容器基于镜像创建,容器的文件系统包括镜像的只读层+可写层,容器进程所产生的的数据均保存在可写层上,一旦容器删除,上面的数据就没有了,除非手动备份下来。而 卷挂载 机制可以让我们把容器中的某个目录和宿主机关联,让容器中的数据持久保存在宿主机上,即使容器删除,产生的数据仍在。
- 当我们开发一个应用时,开发环境在本机,运行环境启动在一个
docker容器中,当我们修改一处之后想看到效果,需要重启容器,这显然比较麻烦。此时可以设置容器与本机的某个目录同步,当我们修改主机上的内容是,不需要同步容器,对容器来说是自动生效的,比如一个 web 应用,修改 index.html 后,刷新之后马上就能看到效果。 - 多个容器运行一组关联服务,共享一些数据。
通过一个 nginx 实例加深理解:
1. 指明宿主机的目录
# 拉取nginx镜像
docker pull nginx:latest
# 创建宿主机目录
mkdir -p /Users/hujiaming/Downloads/nginx_test/index
# 自定义欢迎页内容
cat "<h1> Hello World </h1>" >>> /Users/hujiaming/Downloads/nginx_test/index/index.html
# 将宿主机端口8080映射到容器端口80,将宿主机目录 /Users/hujiaming/Downloads/nginx_test/index 映射到容器目录 /usr/share/nginx/html(这个目录中存放nginx默认的欢迎页index.html)
docker run -d -p 8080:80 -v /Users/hujiaming/Downloads/nginx_test/index:/usr/share/nginx/html --name nginx nginx
此时访问 宿主机 IP:8080,会出现 Hello World 而不是 nginx 的默认欢迎页,当我们修改 nginx_test/index/index.html 内容时,刷新浏览器发现也会同步刷新。
2. 未指定关联的主机目录
docker run -d -p 8080:80 -v /data --name nginx nginx
上述命令只设置了容器的挂载点,并没有指定关联的主机目录。这时候 docker 会自动绑定主机上的一个目录。可以通过 docker inspect <name> 查看:
>>> docker run -d -it -v /data nginx
# 查看得到Container ID为: a369cc1f6efa
>>> docker inspect a369cc1f6efa
# 输出
...
"Mounts": [
{
"Type": "volume",
"Name": "10be4368f4fc5671fd71456f72d4c8f33d9f003d30422aca936b8e56976a886a",
"Source": "/var/lib/docker/volumes/10be4368f4fc5671fd71456f72d4c8f33d9f003d30422aca936b8e56976a886a/_data",
"Destination": "/data",
"Driver": "local",
"Mode": "",
"RW": true,
"Propagation": ""
}
],
...
上面 Mounts 下的每条信息记录了容器上一个挂载点的信息,“Destination” 值是容器的挂载点,“Source"值是对应的主机目录。可以看出这种方式对应的主机目录是自动创建的,其目的不是让在主机上修改,而是让多个容器共享。
此外还可以使用 --volumn-from 参数指定和某个已经存在的容器共享挂载点。
五、 实战
1. 在 Ubuntu19 中安装 docker
# 旧版本中docker叫做 docker , docker.io , docker-engine,如果这些旧版本已经安装,先卸载掉他们
sudo apt-get remove docker docker-engine docker.io containerd runc
# 添加依赖
sudo apt-get update
sudo apt-get install \
apt-transport-https \
ca-certificates \
curl \
gnupg-agent \
software-properties-common
# 添加GPG
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
# 在 /etc/apt/sources.list中添加依赖
sudo add-apt-repository \
"deb [arch=amd64] https://download.docker.com/linux/ubuntu \
$(lsb_release -cs) \
stable"
# 更新
sudo apt-get update
# 安装docker服务
sudo apt-get install docker-ce
2. 启动和关闭容器
# 查看当前已有的image
>>> docker image ls
REPOSITORY TAG IMAGE ID CREATED SIZE
centos latest 67fa590cfc1c 10 hours ago 202MB
ubuntu latest a2a15febcdf3 5 days ago 64.2MB
nginx latest 53f3fd8007f7 3 months ago 109MB
centos 7 9f38484d220f 5 months ago 202MB
jenkins latest cd14cecfdb3a 13 months ago 696MB
# 启动(-it 告诉docker,开启容器的交互模式并将读者当前的shell连接到容器的终端;/bin/bash 是说用户在容器内部想运行bash这个进程)
>>> docker run -it ubuntu:latest /bin/bash
# 不关闭容器而退出容器
>>> 组合键 ctrl + PQ
# 在宿主机器上查看运行的机器
>>> docker container ls
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
a847b8ed22b4 ubuntu:latest "/bin/bash" 41 seconds ago Up 40 seconds dreamy_bardeen
6ccf082c4be6 centos:7 "/bin/bash" 4 hours ago Up 4 hours heuristic_tu
# 连接到运行中的容器(记得将下面的dreamy_bardeen换成你自己的容器名称,在docker container ls结果最后一列)
>>> docker container exec -it dreamy_bardeen bash
# 停止容器
>>> docker container stop dreamy_bardeen
# 杀死容器
>>> docker container rm dreamy_bardeen
3. 多阶段构建
编写如下 go 文件:
# main.go
package main
import (
"fmt"
"github.com/gin-gonic/gin"
"net/http"
)
func main() {
engine := gin.Default()
engine.GET("/hello", func(c *gin.Context) {
name := c.Query("name")
fmt.Println("hello " + name)
c.JSON(http.StatusOK, gin.H{"message": "hello " + name})
})
engine.Run(":8899")
}
使用 go mod :
go mod init demo_go
go mod tidy
对于 Dockerfile 的编写,有三种方案:
方案一:直接使用 golang 全镜像
FROM golang:1.14-alpine
EXPOSE 8899
WORKDIR /go/src/demo_go
COPY . /go/src/demo_go
RUN GOPROXY=https://goproxy.cn,direct go build -v -o main *.go
ENTRYPOINT [ "./main" ]
方案二:使用两个 Dockerfile,第一个编译出可执行二进制,第二个直接将二进制复制进去执行
# cat Dockerfile.build
FROM golang:1.14-alpine
WORKDIR /apps/demo_go
COPY . .
RUN go build -v -o app *.go
# cat Dockerfile.copy
FROM golang:1.14-alpine
WORKDIR /root/
COPY app /root/app
RUN chmod a+x /root/app
EXPOSE 8899
ENTRYPOINT ["/root/app"]
# 这二者通过一个build.sh文件组合在一起
# cat build.sh
#!/bin/bash
echo "start build demo_go:stage1"
docker build -t demo_go:build . -f Dockerfile.build
docker create --name extract demo_go:build
docker cp extract:/apps/demo_go/app ./app
docker rm -f extract
echo "start build demo_go:stage2"
docker build --no-cache -t demo_go:install . -f Dockerfile.copy
rm -rf ./app
方案三:多阶段构建
# 第一阶段,编译出可执行文件
FROM golang:1.14-alpine as builder
WORKDIR /apps
COPY . .
RUN CGO_ENABLED=0 GOOS=linux GOPROXY=https://goproxy.cn,direct go build -v -a -o app *.go
# 第二阶段,将第一阶段编译好的二进制复制进最后一个阶段的容器即可
FROM alpine:latest as prod
RUN apk --no-cache add ca-certificates
WORKDIR /root/
COPY --from=builder /apps/app .
EXPOSE 8899
CMD ["./app"]
分别使用不同的执行构建 image:
# 第一种
docker build -t demo_go:source -f Dockerfile .
# 第二种
bash build.sh
# 第三种
docker build -t demo_go:multi -f Dockerfile.multi .
这三种方案有什么区别?我们看一下各自 image 的大小:
>>> docker image ls
REPOSITORY TAG IMAGE ID SIZE
demo_go copy ab80d3d110b6 401MB
demo_go source 274bf686025c 474MB
demo_go app 7e8207b60f07 394MB
demo_go multi 62b316cc49bd 21.1MB
看出差距了?